Model-Advantage and Value-Aware Models for Model-Based Reinforcement Learning: Bridging the Gap in Theory and Practice
Abstract
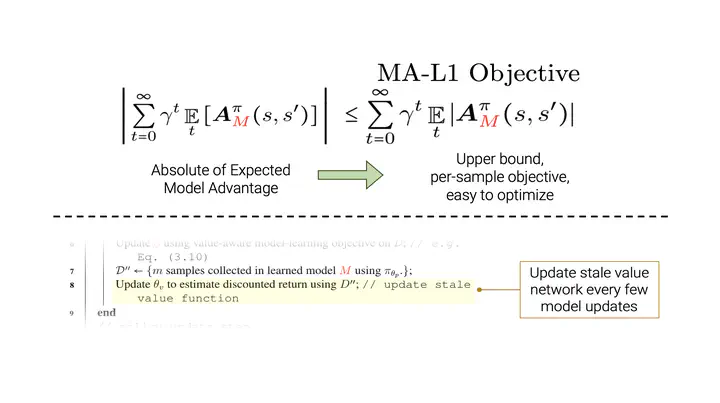
This work shows that value-aware model learning, known for its numerous theoretical benefits, is also practically viable for solving challenging continuous control tasks in prevalent model-based reinforcement learning algorithms. First, we derive a novel value-aware model learning objective by bounding the model-advantage i.e. model performance difference, between two MDPs or models given a fixed policy, achieving superior performance to prior value-aware objectives in most continuous control environments. Second, we identify the issue of stale value estimates in naively substituting value-aware objectives in place of maximum-likelihood in dyna-style model-based RL algorithms. Our proposed remedy to this issue bridges the long-standing gap in theory and practice of value-aware model learning by enabling successful deployment of all value-aware objectives in solving several continuous control robotic manipulation and locomotion tasks. Our results are obtained with minimal modifications to two popular and open-source model-based RL algorithms – SLBO and MBPO, without tuning any existing hyper-parameters, while also demonstrating better performance of value-aware objectives than these baseline in some environments.